



For beginners, Natural Language Processing or NLP is one of the interesting dimension of Artificial Intelligence concerned with the method of communicating between computers and human in a human-like manner hence often called natural language.
One of the most significant barriers that stand against Natural Language Processing is the shortage of training data. Jacob Devlin and Ming-Wei Change, research scientists at Google, explain why it was important for organizations to share labeled datasets:
One of the biggest challenges in natural language processing (NLP) is the shortage of training data. Because NLP is a diversified field with many distinct tasks, most task-specific datasets contain only a few thousand or a few hundred thousand human-labeled training examples. However, modern deep learning-based NLP models see benefits from much larger amounts of data, improving when trained on millions, or billions, of annotated training examples.
Let's also learn little bit about evolution of NLP
Evolution of NLP from dumb to smart
First of all, to cope up with the things changing so fast, let’s take a quick review of NLP’s history.
Usually, in the 1980s, the NLP systems relied upon a rule-based approach, developed by the innovative work of Noam Chomsky who believed that the rules-based method of (transformational-generative grammar) could lead to the development of semantic functions and thus revolutionize machines towards an understanding of speech.
However, machine learning algorithms became increasingly popular in the late 1980s, which led to the adoption of statistical models instead of the rule-based approach.
The big appearance of NLP took place in 2013 with the introduction of the word embeddings for machine learning such as FastText, Word2vec, and Glove.
These word embeddings encapsulate the meaning of a word in vector form after monitoring considerable amounts of text and analyzing each word’s appearance among various contexts across a dataset.
A vector consists of a fixed string of numbers, which helps language become translatable to a machine.
The concept of word embedding is based upon the idea that words with the same meaning would include similar vectors.
The biggest drawback of this first-generation concept was that each word consisted of only one vector. In contrast, each word could have multiple meanings (for example, apple is a fruit, computer, or a smartphone).
To overcome these drawbacks and to introduce machine learning in a much human-centric way, Google released BERT, which has taken us to an inflection point of Artificial Intelligence.
What is BERT? And How is it making a difference?
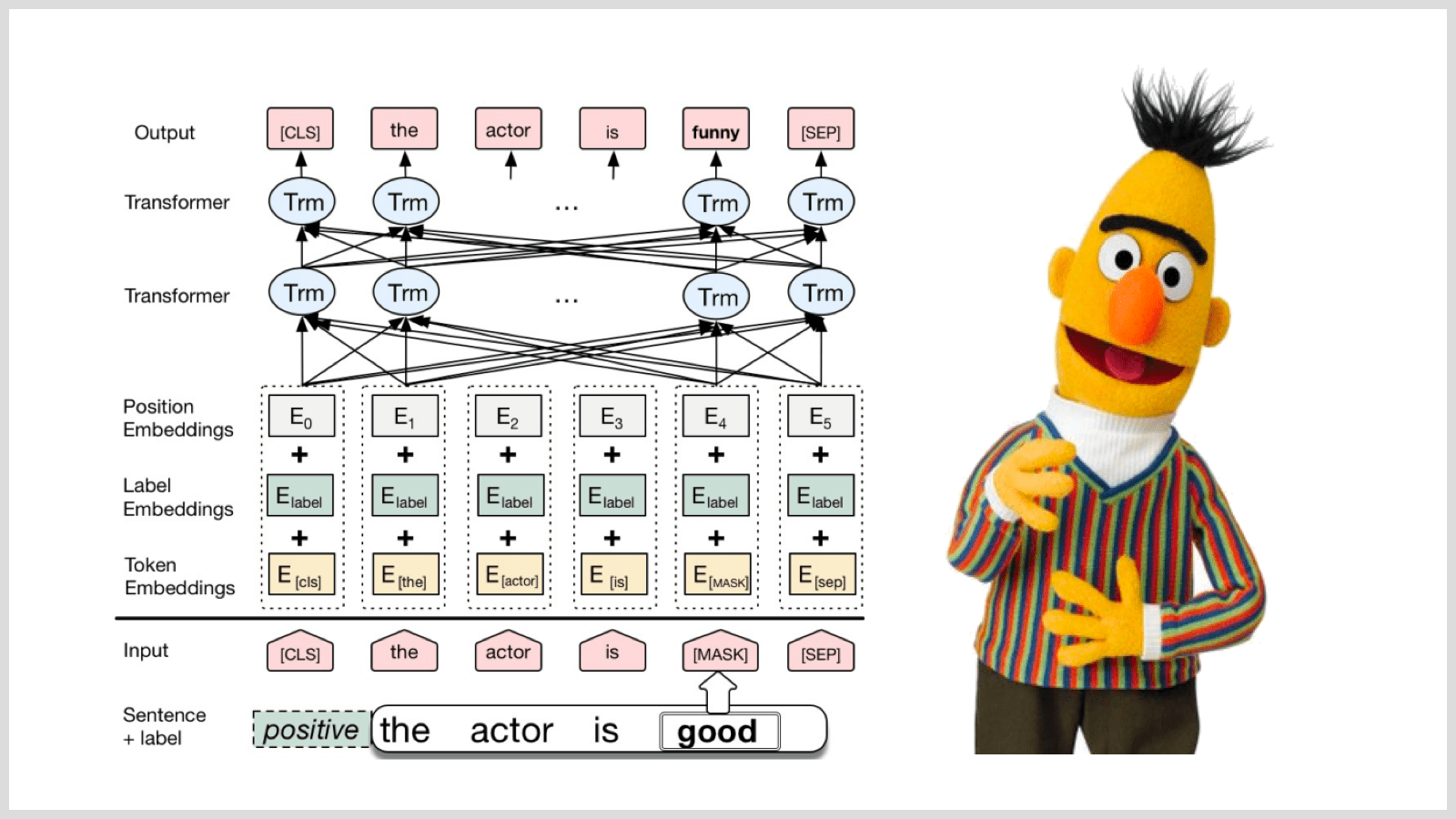
BERT or Bidirectional Encoder Representations From Transformers is a technique for pre-training of NLP published and developed in 2018 by Jacob Devlin and his colleagues from Google.

Bert is used for training general purpose language representation models using a massive datasets that includes generic text from the web like wikipedia and open source books corpus, also referred to as pre-training
BERT’s key innovation is applying the bidirectional training of Transformer, a popular attention model, to language modeling.
BERT can outrange about 11 of the most common NLP tasks, which makes it a catalyst for Natural Language Processing and Understanding.
How BERT works?
BERT uses an entirely different tactic for learning. It is provided with billions of sentences at training time, and it’s asked to predict for a random selection of missing words from the given sentences.
After practicing through the provided corpus of text several times, BERT adopts an excellent understanding of how does a sentence fits together grammatically.
BERT uses a transformer as well, which works as an attention mechanism to learn contextual relations between words (or sub-words) in a text.
In its furnished form, Transformer consists of two separate mechanisms — an encoder to read the text input and a decoder to derive a prediction for the task.
As compared to other directional models that monitor the text input sequentially (right-to-left or left-to-right), the transformer encoder follows the entire sequence of words just at once.
Hence, it is considered as bidirectional, although it would be more accurate to state it as non-directional.
While training the language models, there remains a challenge to define a prediction goal. Many models predict the next word within a sequence (e.g., “My dad came home from___”), a directional approach that intrinsically limits context learning.
To take over this challenge, BERT uses Masked Language Model (MLM) and Next Sentence Prediction (NSP) to minimize the combined loss function of the two strategies.
How is BERT making a difference?
BERT is a competent game changer in natural language processing; some of its mind blowing advantages include:
1. Based on Contextual Model
It means that the generation of word embeddings is based upon the context of word’s preferred use in a sentence, and thus a single word can consist of multiple embeddings.
For example, BERT would derive different embeddings for ‘Apple’ in the following two sentences:
“Apple is good for health,” and “Apple is my favorite brand.”
2. BERT facilitates transfer learning
BERT is pre-trained by Google on Wikipedia books corpus, and now this pre-trained model can be used over other specific datasets like agent <-> customer conversations to build support chatbot for your company.
3. Fast, Stable & Programmable
It is a lot cheaper and quicker to fine-tune the BERT on a small set of domain-specified data, which provided more accurate results rather than training over these domain-specified data from scratch.
The secret formula to skyrocket sales and brand appearance: BERT + FRONTMAN AI
During their start, chatbots acquired a sensational wave by everyone, but later on, they were coined with a negative reputation simply because people preferred to talk to their living counterparts.
BERT has revolutionized chatbots as multifaced and multifunctional chatbots that can better monitor speech and respond relevantly and instantly in realtime, which has provided benefits to various industries including automotive, food, medical, and many more.
The Frontman is a chatbot builder platform developed at Makerobos Innovation Labs that can understand the user’s intent through the input and respond to it correspondingly. The deployment of Frontman at various business sites has triggered their brand engagement rate and uplifted their brand appearance.
As we all know that the BERT is pre-trained by Google on Wikipedia, which clearly states that it has worked over more than a hundred thousand corpus text. By integrating BERT with Frontman many new features can be unleashed, some of them are :
1. Translation
In this digital era, only 26% of the internet population browse in the English language.
The BERT model implementation has enhanced the accuracy of chatbots from 80 % to 93.6 %, which has taken Conversational Commerce towards the next level.
With the help of BERT, Frontman can be designed to interact with users in multiple languages.
![]()
The BERT also takes care of other aspects of translation, including text direction, lexical semantics, and currency, to make your chatbot’s sentences individually adapted to the local language and cultural context for an accurate and understandable translation in the target country: a natural localization process.
2. Proactive comprehension
The BERT model can be used to provide helpful information automatically.
Customers might ask how to pay digitally, how to return a defected item and when the order could be delivered at the doorstep or just the timmings of a showroom.
BERT model in Frontman can help you automate manual tasks such training on business specific intents, entities and preparing FAQs, or reuse chat corpus already available.
Secondly, more sophisticated approach that BERT leverages is the advancement in reading comprehension, which is the ability to read and interpret open domain text and answer questions about it automatically.
3. Active reasoning with questions/answers
Question and answering require a chatbot to develop an artificial intelligence discipline within the fields of information retrieval and natural language processing.
The implementation of the BERT can make your chatbot smarter by automatic retrival of answers to the questions posed by humans in a natural language via active reasoning based on the context derived through the structured database/knowledgebase used for its training.
Besides, it can leverage to classify questions based on the training data through which user can seek information from unstructured collections as well.
Conclusion
BERT has undoubtedly put Machine Learning and Natural Language Processing on a cutting edge. BERT’s ability to provide fine-tuning will extend it into a wide range of practical applications in the future. What are your thoughts about NLP and BERT? Schedule Demo to learn about BERT & Frontman AI
































